Konfiguracja ogólnego i miejscowego OCR
Mechanizm ogólnego OCR w systemie AMODIT służy do odczytania zawartości załączanych do sprawy dokumentów (m.in. PDF). Tak odczytana zawartość jest następnie wykorzystywana przez indekser silnika wyszukiwania Lucene, używanego w AMODIT jako tzw. szybka wyszukiwarka.
Mechanizm miejscowego OCR służy do odczytywania danych bezpośrednio z podglądu dokumentu.
Po wykonaniu instalacji systemu AMODIT należy dorzucić dodatkowe pliki „treningowe” dla OCR w katalogu tymczasowym systemu AMODIT. W szczególności, gdy w logach systemu AMODIT rejestrowany jest komunikat błędu o takiej treści:
GetOCRFromPage failed, message: RunOCR failed, status is OCRDictionaryNotFound
Ścieżkę do fizycznej lokalizacji katalogu tymczasowego na serwerze, gdzie zainstalowany jest AMODIT, można znaleźć w ustawieniach systemowych w parametrze „Temporary Search Folder” (patrz punkt [4] na poniższym obrazku).
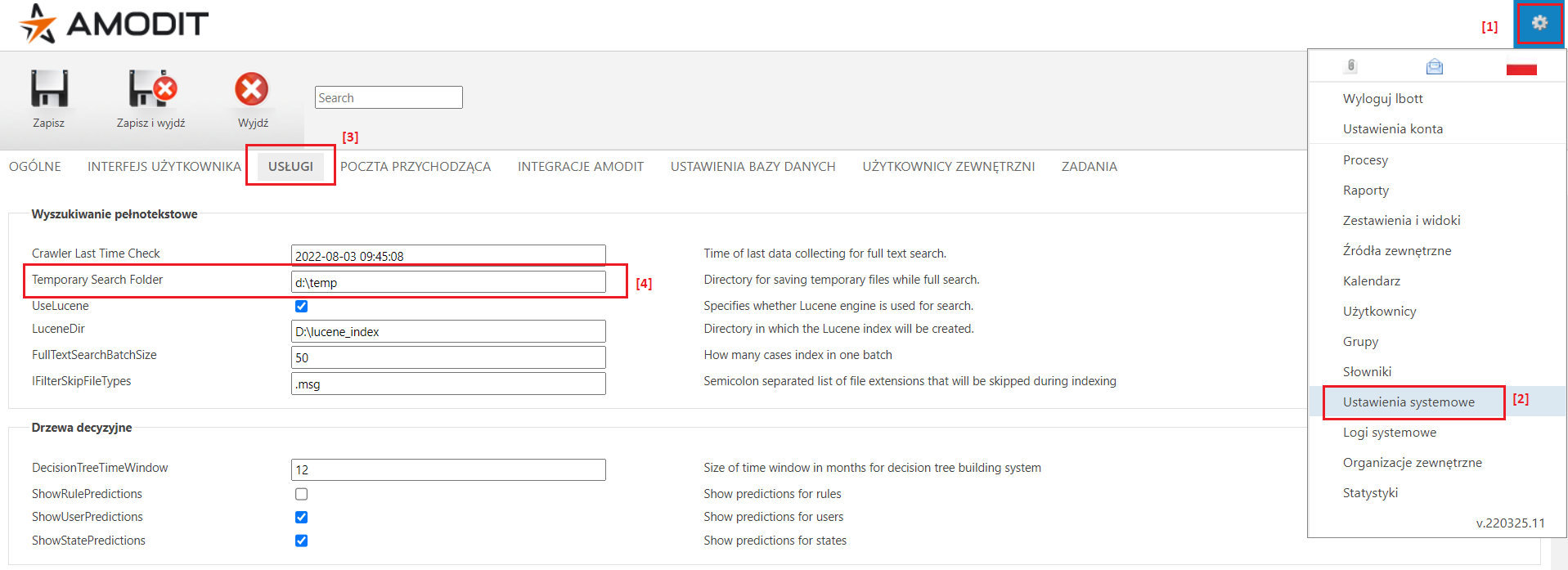
W pierwszej kolejności należy pobrać archiwum ZIP z plikami treningowymi: OCR.zip
Następnie należy go rozpakować w folderze tymczasowym AMODIT’a, tak aby pliki pol.traineddata i eng.traineddata były w podfolderze „ocr” (np.: d:\temp\ocr).
Dla innych języków można pobrać dane stąd tesseract_ocr_4x_language_pack.zip